
parsing your pdfs in r
While it’s fairly straightforward to read a .pdf file into R, we may not want all of the text from our .pdf files to be read in all at once, or into the same row or column of our dataframe. There are parts of our .pdfs we may not want to be included in our analysis, or that we may wish to include as metadata, separated from the main text component of our data set.
One way to deal with this problem is to use what’s called regular expressions, or regex, to select the specific parts of our text files that we wish to have included in your final data set. This activity is called parsing.
At the higheset level of abstraction, a regular expression is a predefined sequence of characters that matches a particular pattern in your data. Combined with string-searching algorithms, regex can be used to search through documents, detect, and extract particular parts you are interested in.
read your pdf article(s) into r using pdftools
Let’s start by reading in a .pdf document - a copy of a recent news editorial on COVID-19 and inequality obtained from ProQuest - using the pdftools library.
#load in library, remmeber to install first if you do not have it already
#install.package("pdftools")
library(pdftools)
#set wd to folder where .pdf file is located
setwd("~/Desktop/personal-website/Blog_Files/parsing-pdf-blog")
#read in .pdf format news article
article_path <- list.files("~/Desktop/personal-website/Blog_Files/parsing-pdf-blog/", pattern = "pdf$")
#read in article using lapply
article <- lapply(article_path, pdf_text)
#convert to chr class
article <- as.character(article)
find the information you want to extract
Next let’s take a look at the original document and get a sense of how it is structured and what kinds of information it contains.
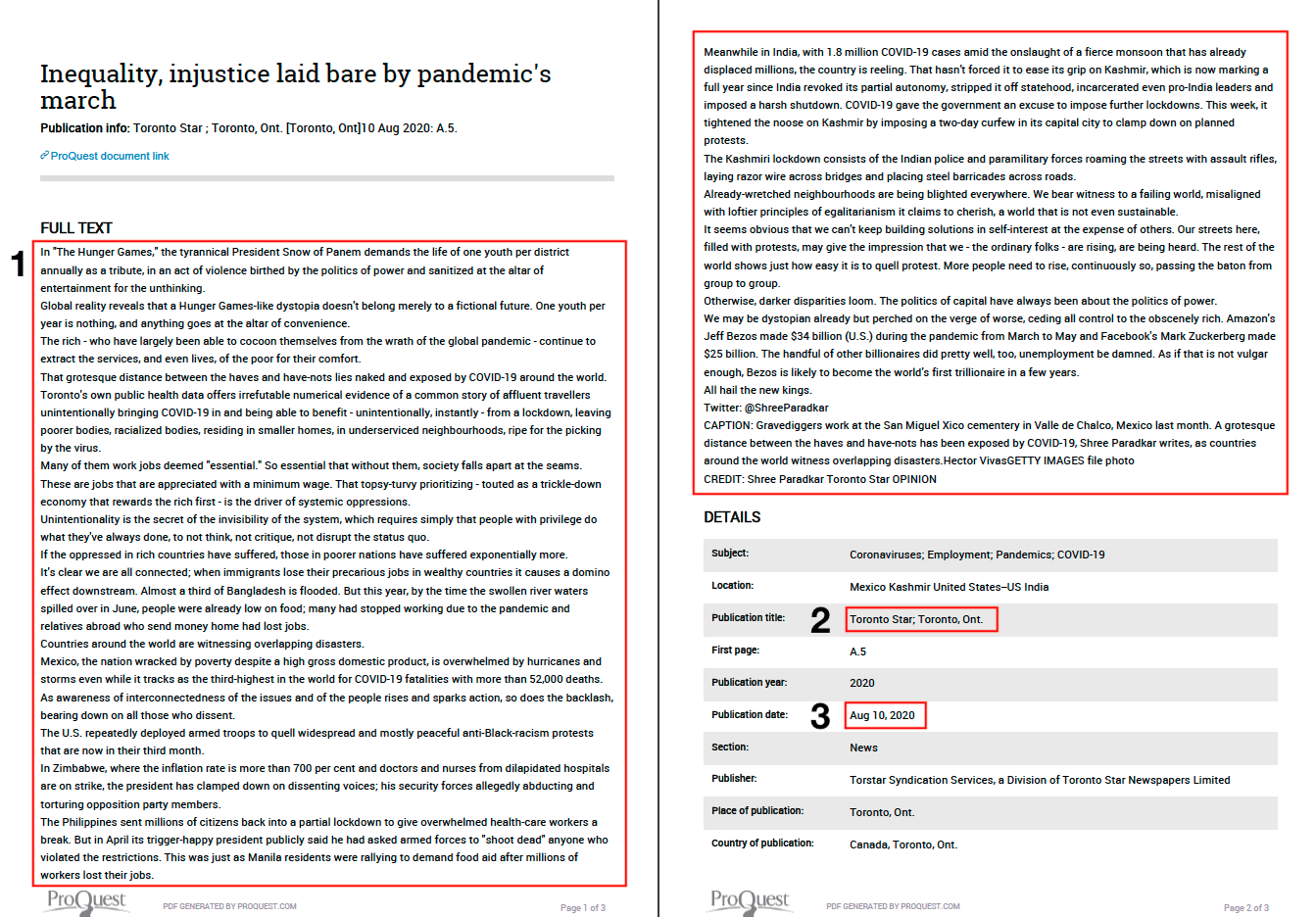
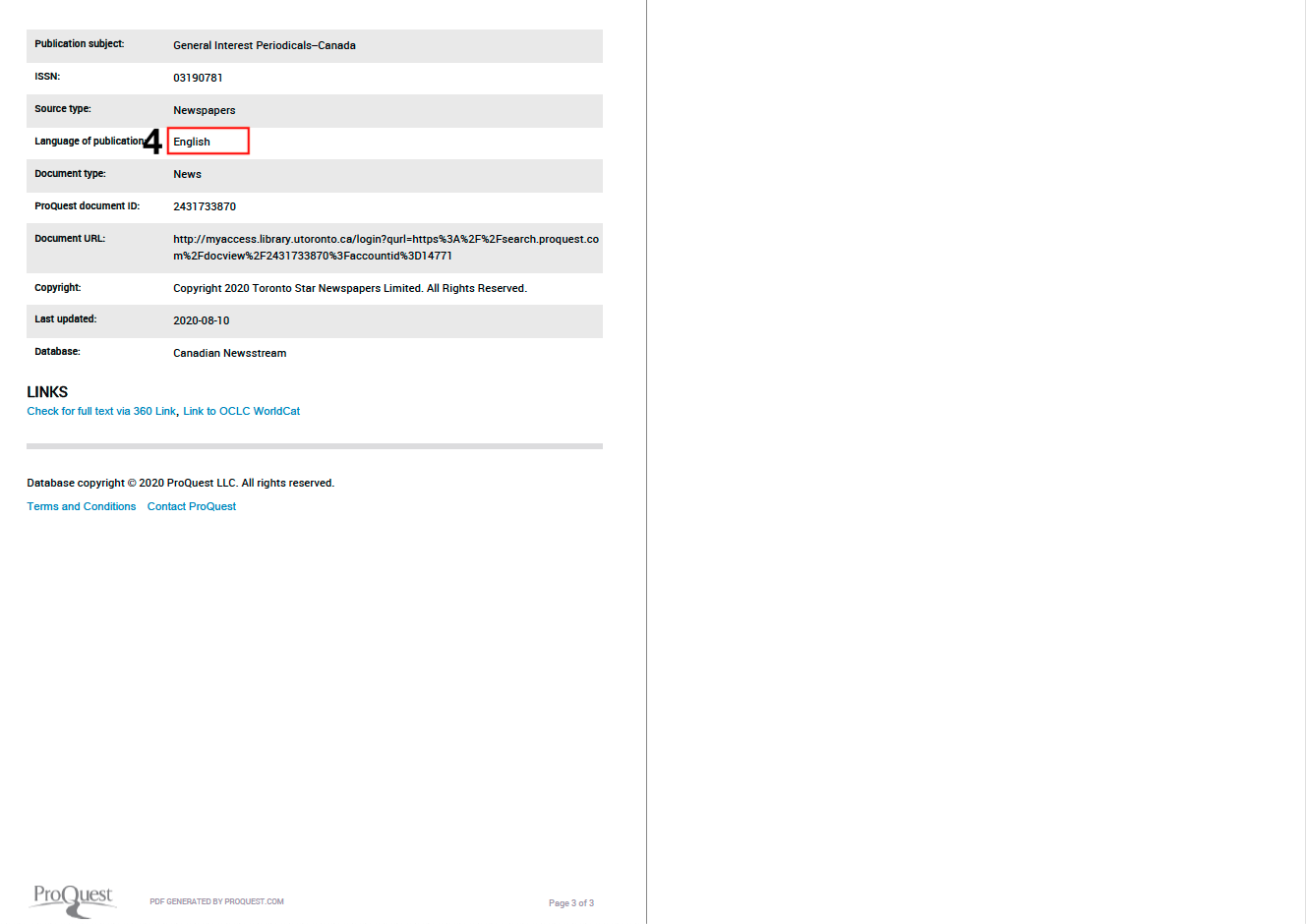
Looking at the original document, let’s say we are interested in the following three elements: (1) the full text of the article; (2) the title of the publisher; (3) the date the article was published; and (4) the language the article was published in.
write a search/extraction function
Now let’s say we want to extract this information from our document (or large list of documents structured in the same way), and store each of the four items in a different column of a dataframe.
To achieve this, we can write a function in R that combines some simple regex with a search/information extraction algorithm. For our search/extraction algorithm, we’ll make use of two functions from the stringr library. The first, str_trim, removes whitespace from the start and end of the information we are extracting. The second, str_extract, will search our document for any information that matches our regex pattern and extract it.
# load in stringr library, remember you may need to install first
library(stringr) # install.packages("stingr")
# create function called get_data, combining regex, str_trim_ and str_extract
get_data <- function(dat) {
list(Full_Text = str_trim(str_extract(dat, "(?<=FULL TEXT)(?s)(.*?)(?=CREDIT)")),
Pub_Title = str_trim(str_extract(dat, "(?<=Publication title:)(.*?)(?=;)")),
Pub_Date = str_trim(str_extract(dat, "(?<=Publication date:)(.*?)(?=\\\\n)")),
Pub_Language = str_trim(str_extract(dat, "(?<=Language of publication:)(.*?)(?=\\\\n)"))
)
}
To understand the function we just wrote, let’s break it down into its component parts.
First, we created an empty vector called get_data, which we assigned our function to, function(dat), where dat simply stands for dataset. The vector get_data in turn becomes the name our function, as we’ll see below when we apply it to our article.
Next, we defined the arguments that our function contains. In this case, we told our function to create a list of four elements, using four separate search/extraction algorithms (a combination of str_trim and str_extract as noted above).
On the left side of each function (i.e., Full_Text =, etc.), we gave the item in our list a name, which will turn become our column names in our final dataframe.
On the right side of the function after the equals sign (i.e., str_trim(str_extract(dat, ...), etc.), we told R the following: stripping the information you extract of leading and tailing white spaces, find any information in our document that matches the following regex pattern, and store that information for us. We do this four times, getting information for Full_Text, Pub_Title, Pub_Date, and Pub_Language, using four different but very similar regular expressions. Let’s take a closer look at these.

We can think of this expression as consisting of four major elements.
First, we tell our search/extraction function what to look for. In this case, we knew ahead of time that the full text for our article was located between the words “FULL TEXT” and “CREDIT” (note that regex is case sensitive). So we start our regular expression by telling our search/extraction algorithm to find the words FULL TEXT, as everything we are interested in comes after this. To translate this into regex, we say "?<=FULL TEXT", which very simply means find the character string in our document that starts with the words “FULL TEXT”.
Next, because there are numerous line breaks in our article (which indicate new paragraphs), we want to make sure that our information detection/extraction algorithm is going toread past these, as we don’t want it to stop extracting information as soon as it hits a new line (which str_extract will by default). To do this, we add "?s" to our expression, which says treat everything as a single line.
Third, we tell our searching/extracting algorithm what information it is that we are actually interested in obtaining. In this case, we are interested in everything between the words “FULL TEXT” and “CREDIT”, so at this point in our regular expression, we’ll say grab everything between the start and end of our expression, represented here as ".*?".
Finally, as we want our detection/extraction algorithm to stop at the word “CREDIT”, we’ll close it off in a similar way to how we opened it, writing "?=CREDIT".
The remaining three regular expressions work in much the same way, the only real differences being that we don’t need to ensure our detection/extraction algorithm reads through line breaks (so we remove this part), and that we are interested in information located between different character patterns. In the case of Pub_Title, we want the information between the words “Publictaion title:” and “;”. And in the case of Pub_Date and Pub_Language, we want the information between the words “Publictaion date:” and “Language of publication:” and a new line break (represented here as four forward slashes and an “n”).
While this might seem a bit strange and hard to wrap your head around at first, with time it will become much easier and more familiar to you.
When writing your own regular expressions, it’s a really useful exercise to first test them using a regular expression tester like this regexr.com, which I rely on heavily. Regular expression cheat sheets are also very useful to have on hand when working in regex.
apply your function to your article
To apply our function to our article, saving the results as a dataframe, we can use a function called map_dfr, which also requires that we have the dplyr library installed.
# load in purrr and dplyr libraries, remmeber to install first if you don't have them
library(dplyr) # install.packages("dplyr")
library(purrr) # install.packages("purrr")
#let's apply our function to our article, saving the results as a dataframe using the map_dfr function
article_df <- map_dfr(article, get_data)
#inspect our results
article_df
We’ve taken our news article, read it into R, and extracted the information we wanted, creating a 1x4 matrix.